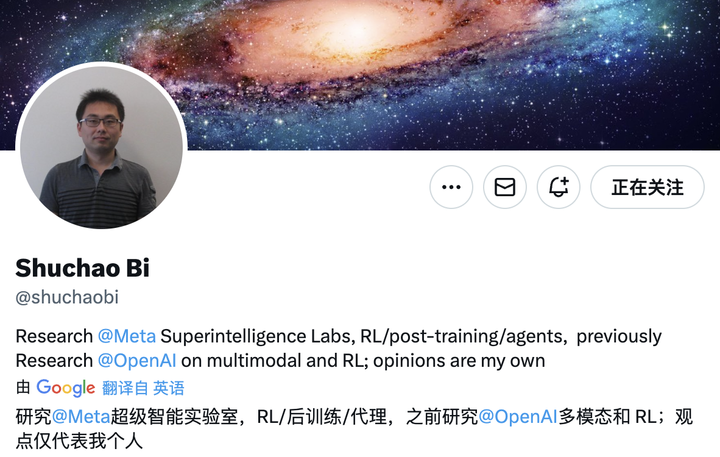
 在过去的两个星期中,AI行业中最受欢迎的产品是人,而不是产品。通常,当我醒来时,我的社交网络时间表会刷新我不会改变汤和药物的消息。 AI的另一个巨人被Cazatalantos猎杀了吗? AI的最佳才能正在成为AI卡车中最恐怖和面向品牌的资产。在这场才艺风暴的核心中,我们找到了非常重要的细节。在指挥大型模型(例如Chatgpt,Gemini和Claude)的研究和开发的主要成员中,中国科学家的比例很高。这种变化并没有突然发生。近年来出现的海浪在美国的AI人才比例增加了。根据Macropolo发表的人工智能2.0的全球跟踪研究研究报告,中国AI的主要研究人员的百分比从2019年至2022年期间从29%增加到47%。Zhipu Research发表的ChatGPT团队的背景研究报告发现,Chatgpt Core的87米表中有9个是中文,超过10%。因此,我们最近回顾了中国IA研究人员的肖像,他们一直关注硅谷的主要公司,并试图总结其中的一些。在研究生阶段,他们通常会招收著名的大学,例如麻省理工学院,斯坦福大学,伯克利,普林斯顿和UIUC,几乎都有高级的高级文档(例如Newlip,ICLR,Siggraph等)。硕士和博士阶段与扎实的学术基础的全球深度学习爆发一致,并且精通工程和团队合作系统。许多角色职业生涯的第一个目的地是与AI产品或平台联系,这些产品或平台以更高的起点和更快的节奏为大型人提供服务。 3ware,在研究强大的多模式起源后,其研究地址G能够通过模式(文本,语音,图像,视频,动作)的统一推理系统,包括RLHF,蒸馏,对准,人类偏好的建模和发音音调评估等具体细节。 4敏金即使经常流动,基本上不得与生态系统隔离。 Google,Meta,Microsoft,Nvidia,Anthrope,OpenAI ...其流程范围涵盖了AI的初创企业和巨头,但是主题和研究技术的积累通常仍然保持一致,从根本上讲,基本上不会改变线索。 Openai→Metashuchao Bishuchao BI毕业于Zhijiang大学数学系,然后在加利福尼亚大学伯克利分校进行了更多研究,获得了统计学和数学博士学位的硕士学位。 2013年至2019年是Google的技术领导者,其主要贡献包括建立一个深入学习的系统,以大大提高GOOG的收入LE广告(10亿美元)。从2019年到2024年,他担任短速探索负责人。在此期间,他共同创建并领导了视频短裤的推荐和发现系统,形成和扩展了大型自动学习设备,以涵盖推荐系统,得分模型,交互式发现,信任和安全性。在2024年加入OpenAI之后,他主要指导该组织进行多模式培训。在他期间,他是GPT-4O和O4-Mini音频模式的炊具。主要促进RLHF,图像/音频/文本文本,多模式代理,语音多模式语音(VS2S),Acolanguage离子的基本视觉模型(VLA),跨模式资格系统等,促进了多模式链推断,语音音调推理,自然的性质/多模式蒸馏和自我-Control。它的主要目的是在训练后建立更通用的多模式AI代理。 Huiwen Chang于2013年,Huiwen Chang毕业于大学的计算机科学学院(YAO课程)tsinghua。然后他去了美国的普林斯顿大学学习博士学位。在计算机科学中。他的研究重点是图像式传输,生成建模和图像处理。他获得了我获得的微软研究所奖学金。在加入OpenAI之前,他在Google担任高级研究科学家,从事六年多的累积工作,发明了由Maskgit和Google Research中的文本生成的图像架构,以及为Maskgit和Muse生成的字节架构的图像架构。文本生成的第一个图像主要基于扩散模型(DALL-E 2,图像等)。这些模型的生产质量较高,但推理较慢和培训较高。 Maskgit和Muse使用“离散生成 +并行”方法,从而大大提高了效率。 Maskgit是生成非自动图像的新起点,但是Muse是一个杰作,可以指导这种方法来生成文本图像。 alt伙计,它们不比稳定的扩散众所周知,它们是学术和工程系统的非常重要的技术基础。此外,它也是上级扩散模型“ Palette:图像扩散中的图像模型”的合着者之一。该文档发表在Siggraph 2022中,并在统一图像中提出了一个图像翻译框架,超过了多个TAREAS的GAN底座和回归线,例如修复图像,阴影和完成。到目前为止,它已经被引用了1,700次以上,这使其成为该领域最具代表性的结果之一。截至2023年6月,他加入了Operai Multimodal团队,合作从事GPT-4O图像生成的功能,继续促进前卫方向,例如产生图像和多模型建模。研究和实施。 Ji Linji Lin主要致力于研究多模式学习,推理系统和合成数据。它有助于多种中心模型,包括GPT-4O,GPT-4.1,GPT-4.5,O3/O4-Mini,操作员和图像生成模型4th。他毕业于Tinua大学的Electronics Engineering(2014-2018)。 Song Han教授是MIT的电子和计算机科学学者。在他的博士阶段,他的研究讲话集中在关键地址上,作为模型压缩,量化,视觉语言建模和稀缺推理。 20他于2023年加入OpenAI,在NVIDIA,Adobe和Google担任内部研究人员,很长一段时间以来,他参与了与MIT中神经网络的加速和推理有关的研究,并积累了深厚的理论基础和工程学的实用经验。从学者的角度来看,它在压缩模型,量化和多模式前有许多高通胀文件。 Google Scholar的总数超过17,800,其代表性结果包括TSM视频理解模型,AWQ硬件识别量化方法,吸烟语言模型和VILA视觉语言模型。它也是GPT-4O系统技术文档的主要作者之一(例如GPT-4O系统卡),并获得了AWQ Paper的最佳MLSYS 2024文件奖。 Hongyurenhongyu Ren获得了北京大学(2014- 2018年)的计算机科学技术学位,并获得了斯坦福大学的计算机科学博士学位(2018 - 2023年)。他获得了许多奖学金,包括Apple,Baidu和Softbank Masason Foundation博士公司,他的研究演讲重点介绍了大型语言模型,知识图形的推理,多模式情报和基本模型评估。在加入OpenAI之前,我在Google,Microsoft和Nvidia上进行了许多实习,即使我在2021年担任苹果的内部研究人员,并参加了Siri问答系统的建设。加入J的Openai之后尤利2023年,汉古顿(Hongyu Ren)参加了多种中央模型的构建,包括GPT-4O,4O-MINI,O1-MINI,O3-MINI,O3,O3和O4-MINI,在培训后引导了设备。用他的话说:“我教模特更快地思考,更加僵化,更敏锐。”在野外学术中,他的Google学术界总数超过17,742,他的高度提及的文件如下:基本模型的风险(引用了6,127次);打开图形参考点(OGB)数据集(3524个约会)等。您的研究包括深度学习,图像生成,大型模态体系结构,多模式推理和高性能计算机科学。在执行歌剧任务期间,Jiahui Yu担任感知团队的负责人,领导着重要项目的开发,例如GPT-4O,GPT-4.1,O3/O4/O4-MINI图像生成模块,并提出并实施了“ Images Thought”识别系统。在此之前,他在Google Deepmind上工作了将近四年,这是一个Palm-2体系结构和建模的中央纳税人与双子座多模式的开发共同设计,并且是多型策略google模式中最重要的技术行李箱之一。他还曾在许多机构的实习经验,包括Nvidia,Adobe,Baidu,Snap,Megvii和Microsoft Research Institute。它的研究内容涵盖了多种准则,包括GAN,客观检测,自动驾驶,模型压缩,图像修复和大型深度学习培训系统。 Jiahui在Google Scholar中有34,500多次任命H 49指数。代表性的结果包括基本的可口图图形模型,由Tex Parti生成的图像模型,Bignus Neuronal网络的可扩展设计以及图像修复技术DeepFill V1和V2,该技术广泛用于Adobe Photopospop中。 Shengjia Zhaoshengjia Zhao毕业于Tsinghua大学计算科学系。他曾经交易E在美国赖斯大学。然后他完成了博士学位。 Universila的计算机Sciencestanford D专注于研究大型模型体系结构,多模式推理和对齐方式的研究。 2022年,他加入Openai,担任中央研发成员,并深入参与了该系统的GPT-4和GPT-4O设计工作。他领导了Chatgpt,GPT-4,所有迷你型号,4.1和O3的研究与开发以及OpenAI的合成数据化学。该小组也领导。他是GPT-4技术报告(引用超过15,000次)和GPT-4O系统卡(引用超过1,300次)的合着者,并参与了多个系统卡的撰写(如OpenAI O1)。它是基本歌剧模型标准化和开放的关键纳税人之一。从学术绩效的角度来看,它有21,000多个Google Scholar的约会,25 h的25 h指数。它获得了许多奖项,包括ICLR 2022,JP Morgan PhD研究员,QualcoMM创新奖学金和Google卓越奖学金。 Google→Metapei Sun于2009年,Pei Sun获得了Tsinghua大学的学位,然后去了Calnegie Mellon大学,获得了他的精通和博士学位,获得了他的精通和掌握,并选择离开博士学位是Google DeepMind的领先研究员,并且在培训了Gexini模型之后,他专注于编程和推理。在培训和实施《双子座》系列模型(包括Gemini 1、1.5、2和2.5)之后,它是思维机制建设的中心纳税人之一。在加入DeepMind之前,PEI在Waymo工作了将近七年,曾担任高级研究科学家,领导了两代Waymo的中央识别模型的研究和开发,并且是自主驾驶感知系统演变的骨干。以前,他担任Google软件的工程师已有五年多了,然后参加了研究以及系统架构的开发,并加入了分布式存储公司Alluxio一年多。 Nexusflow→Nvidia Banghua Zhubanghua Zhu毕业于Tsinghua大学电子工程系,然后去了加利福尼亚大学伯克利分校,在那里他获得了博士学位。他在著名的学者Michael I. Jordan和Zian Aojao领域学习电气和信息学工程。他的研究重点是提高基本模型的效率和安全性,整合统计方法和自动学习理论,并致力于创建开源数据集和可公开的工具。 Sulos的兴趣包括游戏理论,增强学习,人类计算机相互作用和自动学习系统。他的独家文件Chatbot Arena提出了ATO ATO一个由人类偏好推广的大型模型评估平台,这使其成为LLM领域的关键参考点之一。此外,它有助于TES到RLHF地址,人类反馈对准和开源对准模型。 Google Scholar总共有3100多次引用,有23 h指数。这是许多受欢迎的开源项目的主要作者之一,例如“聊天机器人竞技场”,“ Benchbuilder”和“ Starly”。他曾在微软担任研究实习生,在Google的学生研究员中,共同创立了Nexusflow的创业公司,并宣布他于6月加入了Nvidia Star。 Nemotron团队将是主要的研究科学家,并将于今年秋天在华盛顿大学担任助理教授。根据该声明,它将参加诸如培训,评估,人工智能基础设施和智能代理的建设等项目,在Nvidia加入模型并突出了与开发商和学院的深度合作之后,开放的结果是相关的。 Jiantao Jiantao Jiantao Jiao是电气和Informa学院的助理教授加州大学伯克利分校的抽动工程和统计。他于2018年获得斯坦福大学的电气工程博士学位,目前是联合负责人或几个研究中心的成员,包括伯克利理论学习中心(CLIMB),人工智能研究中心(BAIR LAB),信息科学与系统研究所(Bliss)和Ingusto-Nastinal-Nastinal-Nastinal(RDI)的情报研究中心。他的研究重点是生成的AI和基本模型,并且对统计自动学习,增加学习系统的优化理论,隐私和安全性,典型的设计学历ISM和自然语言处理,编码生成,计算机视觉,自动驾驶和机器人技术。与Banghua Zhu一样,他也是Nexusflof的CO -Founders之一,Nvidia正式加入了研究总监和杰出的科学家。乔的总约会达到7259,索引每个34 hing。代表性文件包括“理论补偿鲁棒性和精确度之间的原则”和“悲观的历史”,例如“脱机和模仿学习:与Bangua Zhu的合作”等合作。 Claude→Cursorcatherine Wucatherine Wu担任Claude人类代码的产品经理,专注于构建可靠,可解释和操纵的系统。根据信息,凯瑟琳·吴(Katherine Wu)被AI编程启动光标猎杀,以担任产品经理。在加入Humanidad之前,是著名的风险资本公司Index Venture的合伙人。他工作了将近三年,并深入参与了许多新公司的早期投资和战略支持。他的职业生涯不是从他的投资圈子开始,而是在他的第一个技术职位上。他曾在达格斯特实验室(Dagster Labs)担任工程经理,领导了商业产品的首次开发,并担任早期PRAI的Oduct工程师,参与了几种重要产品。扩展产品的构建和操作。他以前在摩根大通(JPMorgan Chase)进行了定义,并获得了普林斯顿大学的计算机科学学位。当他在学校时,他还去了苏黎世埃德(Eth Zurich)进行交流研究。特斯拉| Phil Duan是Tesla AI的主要软件工程师。他目前负责自动驾驶仪下的车队学习团队,并承诺促进特斯拉自动驾驶系统(FSD)中的“数据识别 +”中心模块的建设。他指导特斯拉团队开发快速高性能的迭代数据,自动标记数百万辆汽车的数据,并强调了数据质量,数量和多样性的个性化优化。在感知方向上,它具有视觉基本模型,对象检测,行为预测,职业网络,流量控制,高精确停车援助系统等许多重要的神经网络的造成。他毕业于乌汉技术大学(Uhan Technology University),获得了光学科学和技术学位,并获得了俄亥俄州大学电气工程博士学位和硕士学位,并获得了飞机研究局,并获得了RTCA William E. Jackson 2019 RTCA奖。
在过去的两个星期中,AI行业中最受欢迎的产品是人,而不是产品。通常,当我醒来时,我的社交网络时间表会刷新我不会改变汤和药物的消息。 AI的另一个巨人被Cazatalantos猎杀了吗? AI的最佳才能正在成为AI卡车中最恐怖和面向品牌的资产。在这场才艺风暴的核心中,我们找到了非常重要的细节。在指挥大型模型(例如Chatgpt,Gemini和Claude)的研究和开发的主要成员中,中国科学家的比例很高。这种变化并没有突然发生。近年来出现的海浪在美国的AI人才比例增加了。根据Macropolo发表的人工智能2.0的全球跟踪研究研究报告,中国AI的主要研究人员的百分比从2019年至2022年期间从29%增加到47%。Zhipu Research发表的ChatGPT团队的背景研究报告发现,Chatgpt Core的87米表中有9个是中文,超过10%。因此,我们最近回顾了中国IA研究人员的肖像,他们一直关注硅谷的主要公司,并试图总结其中的一些。在研究生阶段,他们通常会招收著名的大学,例如麻省理工学院,斯坦福大学,伯克利,普林斯顿和UIUC,几乎都有高级的高级文档(例如Newlip,ICLR,Siggraph等)。硕士和博士阶段与扎实的学术基础的全球深度学习爆发一致,并且精通工程和团队合作系统。许多角色职业生涯的第一个目的地是与AI产品或平台联系,这些产品或平台以更高的起点和更快的节奏为大型人提供服务。 3ware,在研究强大的多模式起源后,其研究地址G能够通过模式(文本,语音,图像,视频,动作)的统一推理系统,包括RLHF,蒸馏,对准,人类偏好的建模和发音音调评估等具体细节。 4敏金即使经常流动,基本上不得与生态系统隔离。 Google,Meta,Microsoft,Nvidia,Anthrope,OpenAI ...其流程范围涵盖了AI的初创企业和巨头,但是主题和研究技术的积累通常仍然保持一致,从根本上讲,基本上不会改变线索。 Openai→Metashuchao Bishuchao BI毕业于Zhijiang大学数学系,然后在加利福尼亚大学伯克利分校进行了更多研究,获得了统计学和数学博士学位的硕士学位。 2013年至2019年是Google的技术领导者,其主要贡献包括建立一个深入学习的系统,以大大提高GOOG的收入LE广告(10亿美元)。从2019年到2024年,他担任短速探索负责人。在此期间,他共同创建并领导了视频短裤的推荐和发现系统,形成和扩展了大型自动学习设备,以涵盖推荐系统,得分模型,交互式发现,信任和安全性。在2024年加入OpenAI之后,他主要指导该组织进行多模式培训。在他期间,他是GPT-4O和O4-Mini音频模式的炊具。主要促进RLHF,图像/音频/文本文本,多模式代理,语音多模式语音(VS2S),Acolanguage离子的基本视觉模型(VLA),跨模式资格系统等,促进了多模式链推断,语音音调推理,自然的性质/多模式蒸馏和自我-Control。它的主要目的是在训练后建立更通用的多模式AI代理。 Huiwen Chang于2013年,Huiwen Chang毕业于大学的计算机科学学院(YAO课程)tsinghua。然后他去了美国的普林斯顿大学学习博士学位。在计算机科学中。他的研究重点是图像式传输,生成建模和图像处理。他获得了我获得的微软研究所奖学金。在加入OpenAI之前,他在Google担任高级研究科学家,从事六年多的累积工作,发明了由Maskgit和Google Research中的文本生成的图像架构,以及为Maskgit和Muse生成的字节架构的图像架构。文本生成的第一个图像主要基于扩散模型(DALL-E 2,图像等)。这些模型的生产质量较高,但推理较慢和培训较高。 Maskgit和Muse使用“离散生成 +并行”方法,从而大大提高了效率。 Maskgit是生成非自动图像的新起点,但是Muse是一个杰作,可以指导这种方法来生成文本图像。 alt伙计,它们不比稳定的扩散众所周知,它们是学术和工程系统的非常重要的技术基础。此外,它也是上级扩散模型“ Palette:图像扩散中的图像模型”的合着者之一。该文档发表在Siggraph 2022中,并在统一图像中提出了一个图像翻译框架,超过了多个TAREAS的GAN底座和回归线,例如修复图像,阴影和完成。到目前为止,它已经被引用了1,700次以上,这使其成为该领域最具代表性的结果之一。截至2023年6月,他加入了Operai Multimodal团队,合作从事GPT-4O图像生成的功能,继续促进前卫方向,例如产生图像和多模型建模。研究和实施。 Ji Linji Lin主要致力于研究多模式学习,推理系统和合成数据。它有助于多种中心模型,包括GPT-4O,GPT-4.1,GPT-4.5,O3/O4-Mini,操作员和图像生成模型4th。他毕业于Tinua大学的Electronics Engineering(2014-2018)。 Song Han教授是MIT的电子和计算机科学学者。在他的博士阶段,他的研究讲话集中在关键地址上,作为模型压缩,量化,视觉语言建模和稀缺推理。 20他于2023年加入OpenAI,在NVIDIA,Adobe和Google担任内部研究人员,很长一段时间以来,他参与了与MIT中神经网络的加速和推理有关的研究,并积累了深厚的理论基础和工程学的实用经验。从学者的角度来看,它在压缩模型,量化和多模式前有许多高通胀文件。 Google Scholar的总数超过17,800,其代表性结果包括TSM视频理解模型,AWQ硬件识别量化方法,吸烟语言模型和VILA视觉语言模型。它也是GPT-4O系统技术文档的主要作者之一(例如GPT-4O系统卡),并获得了AWQ Paper的最佳MLSYS 2024文件奖。 Hongyurenhongyu Ren获得了北京大学(2014- 2018年)的计算机科学技术学位,并获得了斯坦福大学的计算机科学博士学位(2018 - 2023年)。他获得了许多奖学金,包括Apple,Baidu和Softbank Masason Foundation博士公司,他的研究演讲重点介绍了大型语言模型,知识图形的推理,多模式情报和基本模型评估。在加入OpenAI之前,我在Google,Microsoft和Nvidia上进行了许多实习,即使我在2021年担任苹果的内部研究人员,并参加了Siri问答系统的建设。加入J的Openai之后尤利2023年,汉古顿(Hongyu Ren)参加了多种中央模型的构建,包括GPT-4O,4O-MINI,O1-MINI,O3-MINI,O3,O3和O4-MINI,在培训后引导了设备。用他的话说:“我教模特更快地思考,更加僵化,更敏锐。”在野外学术中,他的Google学术界总数超过17,742,他的高度提及的文件如下:基本模型的风险(引用了6,127次);打开图形参考点(OGB)数据集(3524个约会)等。您的研究包括深度学习,图像生成,大型模态体系结构,多模式推理和高性能计算机科学。在执行歌剧任务期间,Jiahui Yu担任感知团队的负责人,领导着重要项目的开发,例如GPT-4O,GPT-4.1,O3/O4/O4-MINI图像生成模块,并提出并实施了“ Images Thought”识别系统。在此之前,他在Google Deepmind上工作了将近四年,这是一个Palm-2体系结构和建模的中央纳税人与双子座多模式的开发共同设计,并且是多型策略google模式中最重要的技术行李箱之一。他还曾在许多机构的实习经验,包括Nvidia,Adobe,Baidu,Snap,Megvii和Microsoft Research Institute。它的研究内容涵盖了多种准则,包括GAN,客观检测,自动驾驶,模型压缩,图像修复和大型深度学习培训系统。 Jiahui在Google Scholar中有34,500多次任命H 49指数。代表性的结果包括基本的可口图图形模型,由Tex Parti生成的图像模型,Bignus Neuronal网络的可扩展设计以及图像修复技术DeepFill V1和V2,该技术广泛用于Adobe Photopospop中。 Shengjia Zhaoshengjia Zhao毕业于Tsinghua大学计算科学系。他曾经交易E在美国赖斯大学。然后他完成了博士学位。 Universila的计算机Sciencestanford D专注于研究大型模型体系结构,多模式推理和对齐方式的研究。 2022年,他加入Openai,担任中央研发成员,并深入参与了该系统的GPT-4和GPT-4O设计工作。他领导了Chatgpt,GPT-4,所有迷你型号,4.1和O3的研究与开发以及OpenAI的合成数据化学。该小组也领导。他是GPT-4技术报告(引用超过15,000次)和GPT-4O系统卡(引用超过1,300次)的合着者,并参与了多个系统卡的撰写(如OpenAI O1)。它是基本歌剧模型标准化和开放的关键纳税人之一。从学术绩效的角度来看,它有21,000多个Google Scholar的约会,25 h的25 h指数。它获得了许多奖项,包括ICLR 2022,JP Morgan PhD研究员,QualcoMM创新奖学金和Google卓越奖学金。 Google→Metapei Sun于2009年,Pei Sun获得了Tsinghua大学的学位,然后去了Calnegie Mellon大学,获得了他的精通和博士学位,获得了他的精通和掌握,并选择离开博士学位是Google DeepMind的领先研究员,并且在培训了Gexini模型之后,他专注于编程和推理。在培训和实施《双子座》系列模型(包括Gemini 1、1.5、2和2.5)之后,它是思维机制建设的中心纳税人之一。在加入DeepMind之前,PEI在Waymo工作了将近七年,曾担任高级研究科学家,领导了两代Waymo的中央识别模型的研究和开发,并且是自主驾驶感知系统演变的骨干。以前,他担任Google软件的工程师已有五年多了,然后参加了研究以及系统架构的开发,并加入了分布式存储公司Alluxio一年多。 Nexusflow→Nvidia Banghua Zhubanghua Zhu毕业于Tsinghua大学电子工程系,然后去了加利福尼亚大学伯克利分校,在那里他获得了博士学位。他在著名的学者Michael I. Jordan和Zian Aojao领域学习电气和信息学工程。他的研究重点是提高基本模型的效率和安全性,整合统计方法和自动学习理论,并致力于创建开源数据集和可公开的工具。 Sulos的兴趣包括游戏理论,增强学习,人类计算机相互作用和自动学习系统。他的独家文件Chatbot Arena提出了ATO ATO一个由人类偏好推广的大型模型评估平台,这使其成为LLM领域的关键参考点之一。此外,它有助于TES到RLHF地址,人类反馈对准和开源对准模型。 Google Scholar总共有3100多次引用,有23 h指数。这是许多受欢迎的开源项目的主要作者之一,例如“聊天机器人竞技场”,“ Benchbuilder”和“ Starly”。他曾在微软担任研究实习生,在Google的学生研究员中,共同创立了Nexusflow的创业公司,并宣布他于6月加入了Nvidia Star。 Nemotron团队将是主要的研究科学家,并将于今年秋天在华盛顿大学担任助理教授。根据该声明,它将参加诸如培训,评估,人工智能基础设施和智能代理的建设等项目,在Nvidia加入模型并突出了与开发商和学院的深度合作之后,开放的结果是相关的。 Jiantao Jiantao Jiantao Jiao是电气和Informa学院的助理教授加州大学伯克利分校的抽动工程和统计。他于2018年获得斯坦福大学的电气工程博士学位,目前是联合负责人或几个研究中心的成员,包括伯克利理论学习中心(CLIMB),人工智能研究中心(BAIR LAB),信息科学与系统研究所(Bliss)和Ingusto-Nastinal-Nastinal-Nastinal(RDI)的情报研究中心。他的研究重点是生成的AI和基本模型,并且对统计自动学习,增加学习系统的优化理论,隐私和安全性,典型的设计学历ISM和自然语言处理,编码生成,计算机视觉,自动驾驶和机器人技术。与Banghua Zhu一样,他也是Nexusflof的CO -Founders之一,Nvidia正式加入了研究总监和杰出的科学家。乔的总约会达到7259,索引每个34 hing。代表性文件包括“理论补偿鲁棒性和精确度之间的原则”和“悲观的历史”,例如“脱机和模仿学习:与Bangua Zhu的合作”等合作。 Claude→Cursorcatherine Wucatherine Wu担任Claude人类代码的产品经理,专注于构建可靠,可解释和操纵的系统。根据信息,凯瑟琳·吴(Katherine Wu)被AI编程启动光标猎杀,以担任产品经理。在加入Humanidad之前,是著名的风险资本公司Index Venture的合伙人。他工作了将近三年,并深入参与了许多新公司的早期投资和战略支持。他的职业生涯不是从他的投资圈子开始,而是在他的第一个技术职位上。他曾在达格斯特实验室(Dagster Labs)担任工程经理,领导了商业产品的首次开发,并担任早期PRAI的Oduct工程师,参与了几种重要产品。扩展产品的构建和操作。他以前在摩根大通(JPMorgan Chase)进行了定义,并获得了普林斯顿大学的计算机科学学位。当他在学校时,他还去了苏黎世埃德(Eth Zurich)进行交流研究。特斯拉| Phil Duan是Tesla AI的主要软件工程师。他目前负责自动驾驶仪下的车队学习团队,并承诺促进特斯拉自动驾驶系统(FSD)中的“数据识别 +”中心模块的建设。他指导特斯拉团队开发快速高性能的迭代数据,自动标记数百万辆汽车的数据,并强调了数据质量,数量和多样性的个性化优化。在感知方向上,它具有视觉基本模型,对象检测,行为预测,职业网络,流量控制,高精确停车援助系统等许多重要的神经网络的造成。他毕业于乌汉技术大学(Uhan Technology University),获得了光学科学和技术学位,并获得了俄亥俄州大学电气工程博士学位和硕士学位,并获得了飞机研究局,并获得了RTCA William E. Jackson 2019 RTCA奖。
在美国最昂贵的
在过去的两个星期中,AI行业中最受欢迎的产品是人,而不是产品。通常,当我醒来时,我的社交网络时间表会刷新我不会改变汤和药物的消息。 AI的另一个巨人被Cazatalantos猎杀了吗? AI的最佳才能正在成为AI卡车中最恐怖和面向品牌的资产。在这场才艺风暴的核心中,我们找到了非常重要的细节。在指挥大型模型(例如Chatgpt,Gemini和Claude)的研究和开发的主要成员中,中国科学家的比例很高。这种变化并没有突然发生。近年来出现的海浪在美国的AI人才比例增加了。根据Macropolo发表的人工智能2.0的全球跟踪研究研究报告,中国AI的主要研究人员的百分比从2019年至2022年期间从29%增加到47%。Zhipu Research发表的ChatGPT团队的背景研究报告发现,Chatgpt Core的87米表中有9个是中文,超过10%。因此,我们最近回顾了中国IA研究人员的肖像,他们一直关注硅谷的主要公司,并试图总结其中的一些。在研究生阶段,他们通常会招收著名的大学,例如麻省理工学院,斯坦福大学,伯克利,普林斯顿和UIUC,几乎都有高级的高级文档(例如Newlip,ICLR,Siggraph等)。硕士和博士阶段与扎实的学术基础的全球深度学习爆发一致,并且精通工程和团队合作系统。许多角色职业生涯的第一个目的地是与AI产品或平台联系,这些产品或平台以更高的起点和更快的节奏为大型人提供服务。 3ware,在研究强大的多模式起源后,其研究地址G能够通过模式(文本,语音,图像,视频,动作)的统一推理系统,包括RLHF,蒸馏,对准,人类偏好的建模和发音音调评估等具体细节。 4敏金即使经常流动,基本上不得与生态系统隔离。 Google,Meta,Microsoft,Nvidia,Anthrope,OpenAI ...其流程范围涵盖了AI的初创企业和巨头,但是主题和研究技术的积累通常仍然保持一致,从根本上讲,基本上不会改变线索。 Openai→Metashuchao Bishuchao BI毕业于Zhijiang大学数学系,然后在加利福尼亚大学伯克利分校进行了更多研究,获得了统计学和数学博士学位的硕士学位。 2013年至2019年是Google的技术领导者,其主要贡献包括建立一个深入学习的系统,以大大提高GOOG的收入LE广告(10亿美元)。从2019年到2024年,他担任短速探索负责人。在此期间,他共同创建并领导了视频短裤的推荐和发现系统,形成和扩展了大型自动学习设备,以涵盖推荐系统,得分模型,交互式发现,信任和安全性。在2024年加入OpenAI之后,他主要指导该组织进行多模式培训。在他期间,他是GPT-4O和O4-Mini音频模式的炊具。主要促进RLHF,图像/音频/文本文本,多模式代理,语音多模式语音(VS2S),Acolanguage离子的基本视觉模型(VLA),跨模式资格系统等,促进了多模式链推断,语音音调推理,自然的性质/多模式蒸馏和自我-Control。它的主要目的是在训练后建立更通用的多模式AI代理。 Huiwen Chang于2013年,Huiwen Chang毕业于大学的计算机科学学院(YAO课程)tsinghua。然后他去了美国的普林斯顿大学学习博士学位。在计算机科学中。他的研究重点是图像式传输,生成建模和图像处理。他获得了我获得的微软研究所奖学金。在加入OpenAI之前,他在Google担任高级研究科学家,从事六年多的累积工作,发明了由Maskgit和Google Research中的文本生成的图像架构,以及为Maskgit和Muse生成的字节架构的图像架构。文本生成的第一个图像主要基于扩散模型(DALL-E 2,图像等)。这些模型的生产质量较高,但推理较慢和培训较高。 Maskgit和Muse使用“离散生成 +并行”方法,从而大大提高了效率。 Maskgit是生成非自动图像的新起点,但是Muse是一个杰作,可以指导这种方法来生成文本图像。 alt伙计,它们不比稳定的扩散众所周知,它们是学术和工程系统的非常重要的技术基础。此外,它也是上级扩散模型“ Palette:图像扩散中的图像模型”的合着者之一。该文档发表在Siggraph 2022中,并在统一图像中提出了一个图像翻译框架,超过了多个TAREAS的GAN底座和回归线,例如修复图像,阴影和完成。到目前为止,它已经被引用了1,700次以上,这使其成为该领域最具代表性的结果之一。截至2023年6月,他加入了Operai Multimodal团队,合作从事GPT-4O图像生成的功能,继续促进前卫方向,例如产生图像和多模型建模。研究和实施。 Ji Linji Lin主要致力于研究多模式学习,推理系统和合成数据。它有助于多种中心模型,包括GPT-4O,GPT-4.1,GPT-4.5,O3/O4-Mini,操作员和图像生成模型4th。他毕业于Tinua大学的Electronics Engineering(2014-2018)。 Song Han教授是MIT的电子和计算机科学学者。在他的博士阶段,他的研究讲话集中在关键地址上,作为模型压缩,量化,视觉语言建模和稀缺推理。 20他于2023年加入OpenAI,在NVIDIA,Adobe和Google担任内部研究人员,很长一段时间以来,他参与了与MIT中神经网络的加速和推理有关的研究,并积累了深厚的理论基础和工程学的实用经验。从学者的角度来看,它在压缩模型,量化和多模式前有许多高通胀文件。 Google Scholar的总数超过17,800,其代表性结果包括TSM视频理解模型,AWQ硬件识别量化方法,吸烟语言模型和VILA视觉语言模型。它也是GPT-4O系统技术文档的主要作者之一(例如GPT-4O系统卡),并获得了AWQ Paper的最佳MLSYS 2024文件奖。 Hongyurenhongyu Ren获得了北京大学(2014- 2018年)的计算机科学技术学位,并获得了斯坦福大学的计算机科学博士学位(2018 - 2023年)。他获得了许多奖学金,包括Apple,Baidu和Softbank Masason Foundation博士公司,他的研究演讲重点介绍了大型语言模型,知识图形的推理,多模式情报和基本模型评估。在加入OpenAI之前,我在Google,Microsoft和Nvidia上进行了许多实习,即使我在2021年担任苹果的内部研究人员,并参加了Siri问答系统的建设。加入J的Openai之后尤利2023年,汉古顿(Hongyu Ren)参加了多种中央模型的构建,包括GPT-4O,4O-MINI,O1-MINI,O3-MINI,O3,O3和O4-MINI,在培训后引导了设备。用他的话说:“我教模特更快地思考,更加僵化,更敏锐。”在野外学术中,他的Google学术界总数超过17,742,他的高度提及的文件如下:基本模型的风险(引用了6,127次);打开图形参考点(OGB)数据集(3524个约会)等。您的研究包括深度学习,图像生成,大型模态体系结构,多模式推理和高性能计算机科学。在执行歌剧任务期间,Jiahui Yu担任感知团队的负责人,领导着重要项目的开发,例如GPT-4O,GPT-4.1,O3/O4/O4-MINI图像生成模块,并提出并实施了“ Images Thought”识别系统。在此之前,他在Google Deepmind上工作了将近四年,这是一个Palm-2体系结构和建模的中央纳税人与双子座多模式的开发共同设计,并且是多型策略google模式中最重要的技术行李箱之一。他还曾在许多机构的实习经验,包括Nvidia,Adobe,Baidu,Snap,Megvii和Microsoft Research Institute。它的研究内容涵盖了多种准则,包括GAN,客观检测,自动驾驶,模型压缩,图像修复和大型深度学习培训系统。 Jiahui在Google Scholar中有34,500多次任命H 49指数。代表性的结果包括基本的可口图图形模型,由Tex Parti生成的图像模型,Bignus Neuronal网络的可扩展设计以及图像修复技术DeepFill V1和V2,该技术广泛用于Adobe Photopospop中。 Shengjia Zhaoshengjia Zhao毕业于Tsinghua大学计算科学系。他曾经交易E在美国赖斯大学。然后他完成了博士学位。 Universila的计算机Sciencestanford D专注于研究大型模型体系结构,多模式推理和对齐方式的研究。 2022年,他加入Openai,担任中央研发成员,并深入参与了该系统的GPT-4和GPT-4O设计工作。他领导了Chatgpt,GPT-4,所有迷你型号,4.1和O3的研究与开发以及OpenAI的合成数据化学。该小组也领导。他是GPT-4技术报告(引用超过15,000次)和GPT-4O系统卡(引用超过1,300次)的合着者,并参与了多个系统卡的撰写(如OpenAI O1)。它是基本歌剧模型标准化和开放的关键纳税人之一。从学术绩效的角度来看,它有21,000多个Google Scholar的约会,25 h的25 h指数。它获得了许多奖项,包括ICLR 2022,JP Morgan PhD研究员,QualcoMM创新奖学金和Google卓越奖学金。 Google→Metapei Sun于2009年,Pei Sun获得了Tsinghua大学的学位,然后去了Calnegie Mellon大学,获得了他的精通和博士学位,获得了他的精通和掌握,并选择离开博士学位是Google DeepMind的领先研究员,并且在培训了Gexini模型之后,他专注于编程和推理。在培训和实施《双子座》系列模型(包括Gemini 1、1.5、2和2.5)之后,它是思维机制建设的中心纳税人之一。在加入DeepMind之前,PEI在Waymo工作了将近七年,曾担任高级研究科学家,领导了两代Waymo的中央识别模型的研究和开发,并且是自主驾驶感知系统演变的骨干。以前,他担任Google软件的工程师已有五年多了,然后参加了研究以及系统架构的开发,并加入了分布式存储公司Alluxio一年多。 Nexusflow→Nvidia Banghua Zhubanghua Zhu毕业于Tsinghua大学电子工程系,然后去了加利福尼亚大学伯克利分校,在那里他获得了博士学位。他在著名的学者Michael I. Jordan和Zian Aojao领域学习电气和信息学工程。他的研究重点是提高基本模型的效率和安全性,整合统计方法和自动学习理论,并致力于创建开源数据集和可公开的工具。 Sulos的兴趣包括游戏理论,增强学习,人类计算机相互作用和自动学习系统。他的独家文件Chatbot Arena提出了ATO ATO一个由人类偏好推广的大型模型评估平台,这使其成为LLM领域的关键参考点之一。此外,它有助于TES到RLHF地址,人类反馈对准和开源对准模型。 Google Scholar总共有3100多次引用,有23 h指数。这是许多受欢迎的开源项目的主要作者之一,例如“聊天机器人竞技场”,“ Benchbuilder”和“ Starly”。他曾在微软担任研究实习生,在Google的学生研究员中,共同创立了Nexusflow的创业公司,并宣布他于6月加入了Nvidia Star。 Nemotron团队将是主要的研究科学家,并将于今年秋天在华盛顿大学担任助理教授。根据该声明,它将参加诸如培训,评估,人工智能基础设施和智能代理的建设等项目,在Nvidia加入模型并突出了与开发商和学院的深度合作之后,开放的结果是相关的。 Jiantao Jiantao Jiantao Jiao是电气和Informa学院的助理教授加州大学伯克利分校的抽动工程和统计。他于2018年获得斯坦福大学的电气工程博士学位,目前是联合负责人或几个研究中心的成员,包括伯克利理论学习中心(CLIMB),人工智能研究中心(BAIR LAB),信息科学与系统研究所(Bliss)和Ingusto-Nastinal-Nastinal-Nastinal(RDI)的情报研究中心。他的研究重点是生成的AI和基本模型,并且对统计自动学习,增加学习系统的优化理论,隐私和安全性,典型的设计学历ISM和自然语言处理,编码生成,计算机视觉,自动驾驶和机器人技术。与Banghua Zhu一样,他也是Nexusflof的CO -Founders之一,Nvidia正式加入了研究总监和杰出的科学家。乔的总约会达到7259,索引每个34 hing。代表性文件包括“理论补偿鲁棒性和精确度之间的原则”和“悲观的历史”,例如“脱机和模仿学习:与Bangua Zhu的合作”等合作。 Claude→Cursorcatherine Wucatherine Wu担任Claude人类代码的产品经理,专注于构建可靠,可解释和操纵的系统。根据信息,凯瑟琳·吴(Katherine Wu)被AI编程启动光标猎杀,以担任产品经理。在加入Humanidad之前,是著名的风险资本公司Index Venture的合伙人。他工作了将近三年,并深入参与了许多新公司的早期投资和战略支持。他的职业生涯不是从他的投资圈子开始,而是在他的第一个技术职位上。他曾在达格斯特实验室(Dagster Labs)担任工程经理,领导了商业产品的首次开发,并担任早期PRAI的Oduct工程师,参与了几种重要产品。扩展产品的构建和操作。他以前在摩根大通(JPMorgan Chase)进行了定义,并获得了普林斯顿大学的计算机科学学位。当他在学校时,他还去了苏黎世埃德(Eth Zurich)进行交流研究。特斯拉| Phil Duan是Tesla AI的主要软件工程师。他目前负责自动驾驶仪下的车队学习团队,并承诺促进特斯拉自动驾驶系统(FSD)中的“数据识别 +”中心模块的建设。他指导特斯拉团队开发快速高性能的迭代数据,自动标记数百万辆汽车的数据,并强调了数据质量,数量和多样性的个性化优化。在感知方向上,它具有视觉基本模型,对象检测,行为预测,职业网络,流量控制,高精确停车援助系统等许多重要的神经网络的造成。他毕业于乌汉技术大学(Uhan Technology University),获得了光学科学和技术学位,并获得了俄亥俄州大学电气工程博士学位和硕士学位,并获得了飞机研究局,并获得了RTCA William E. Jackson 2019 RTCA奖。
